
I just spent a long slog sorting out why I could not connect to my SSIS instance remotely. I work in a very secure environment requiring network approval for any and all ports. According to the following article, I was under the impression that a request to open incoming traffic on port 135, to a specific IP, would allow SQL Server Management Studio, on that specific IP, to connect remotely to SSIS:
After opening port 135, I was receiving the error message in the title of this article:
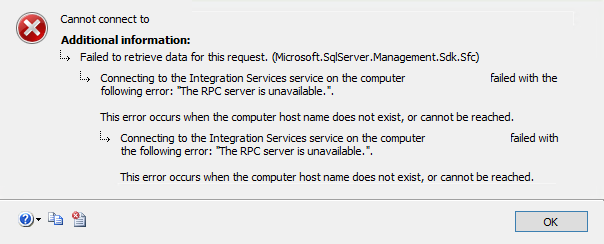
- There are no named instances for SSIS, check your Server Name
- You may need to open port 135
- Maybe it's sufficient SSIS server permissions
- Is the RPC service started?
- It could be a double hop authentication issue
- Is your DCOM Config for Microsoft SQL Server Integration Services configured correctly?
- Configure your firewall to allow MsDtsSrvr.exe
- Try using the IP, maybe it's netbios
As you can imagine, none of these were the solution to my problem. The root cause is that SSIS is using RPC, which has a large dynamic port range. This article describes what's going on with RPC, and has commands for identifying the existing RPC dynamic port range and how to set the range:
For example this command will show you the existing port range:
netsh int ipv4 show dynamicport tcp
For what it's worth, here are a few articles I waded through before I found the solution:
https://stackoverflow.com/questions/48241221/ssis-the-rpc-server-is-unavailable
https://itluke.online/2017/11/08/solved-exception-from-hresult-0x800706ba/